Rozpowszechnienie ataków typu prompt injection oraz brak niezawodnych metod ich blokowania skutecznie utrudniły rozwój agentowych systemów opartych o duże modele językowe (LLM). Większość rozwiązań, które opisałem w poprzednim artykule, ma charakter probabilistyczny i nie daje realnych gwarancji bezpieczeństwa. Jedno z nich jednak się wyróżniało. Szczególną uwagę zwróciłem na podejście oparte na wzorcach projektowych jako takie, które w przyszłości może doprowadzić do stworzenia bardziej ogólnego i solidnego zabezpieczenia przed atakami typu prompt injection.
Istnieją pewne przesłanki, by sądzić, że ta przyszłość właśnie się zaczyna i ten artykuł będzie próbą jej zbadania.
Wzorce projektowe
Pojęcie „wzorzec projektowy” pochodzi ze świata tradycyjnego programowania, które z kolei zaczerpnęło je z architektury. Oznacza ono ogólne rozwiązanie dla często występującego problemu. Nie jest to gotowy kawałek kodu, lecz raczej sposób na zaprojektowanie systemu tak, by osiągnąć konkretny cel. Podobnie jest z wzorcami projektowymi dla systemów opartych na LLM. To ogólne koncepcje dotyczące tego, jak strukturyzować system wykorzystujący modele językowe.
Niektóre z tych wzorców są zaprojektowane specjalnie po to, by chronić system przed atakami typu Prompt Injection.
Dual LLM
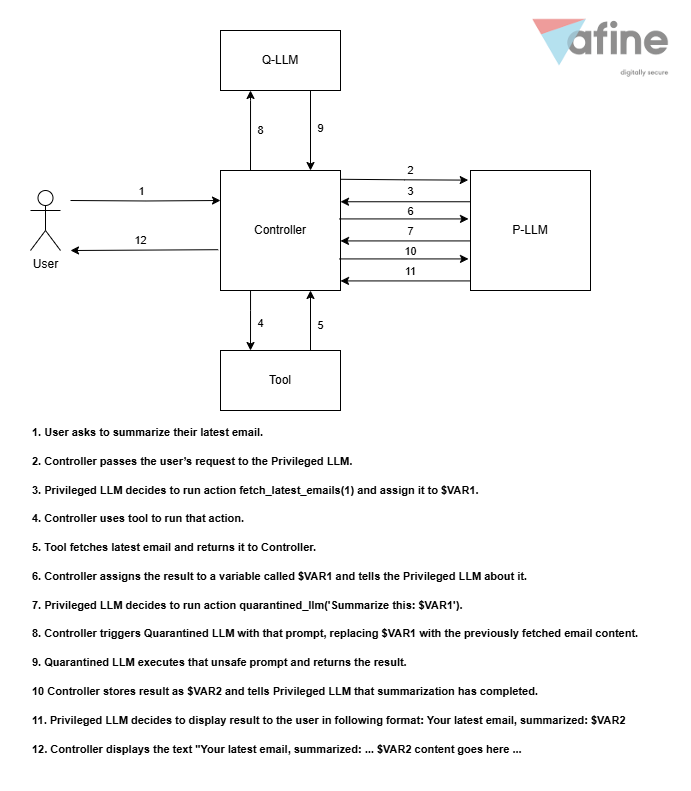
Wzorzec projektowy Dual LLM został zaproponowany przez Simona Willisona w jego wpisie blogowym z 2023 roku. Główna idea polega na rozdzieleniu zadań pomiędzy dwa modele: Uprzywilejowany (ang. Privileged) LLM (P-LLM) oraz Izolowany (ang. Quarantined) LLM (Q-LLM).
Uprzywilejowany LLM ma dostęp jedynie do zaufanych danych wejściowych – zwykle będą to zapytania użytkownika. P-LLM ma też dostęp do narzędzi – może wysyłać e-maile, modyfikować kalendarz, rezerwować loty itp.
Izolowany LLM obsługuje dane niepewne – czyli wszystkie te, które mogą zawierać szkodliwe wstrzyknięcia promptów. Zakłada się, że ten model może zostać skompromitowany, dlatego nie ma on dostępu do żadnych narzędzi, a jego output jest traktowany jako niepewny.
Bezpieczeństwo tej architektury wynika z wyraźnego rozdzielenia ról – surowe dane wyjściowe z Q-LLM nigdy nie powinny trafiać bezpośrednio jako dane wejściowe do P-LLM. Oznacza to, że Uprzywilejowany LLM nigdy nie otrzyma złośliwego promptu – a tym samym jest odporny na tego typu ataki.
Interakcje Uprzywilejowanego LLM z narzędziami, użytkownikiem i Izolowanym LLM są zarządzane przez Kontroler – zwykły komponent programistyczny, a nie model językowy.
Poniżej jest uproszczony schemat działania wzorca Dual LLM dla prostego zapytania użytkownika na przykładzie zapożyczonym z artykułu Willisona:
Nawet sam autor tej koncepcji przyznał, że wzorzec ten ma wiele niedoskonałości. Mimo tych wad jest to ciekawa propozycja, na której można zbudować solidniejsze zabezpieczenia przed atakami typu prompt injection. Właśnie na tej idei bazował zespół Google DeepMind – i o tym będzie dalsza część artykułu.
CaMeL
Jakiś czas temu zespół DeepMind opublikował artykuł opisujący mechanizm obronny o nazwie CaMeL (Capabilities for Machine Learning). Inspiracją do jego powstania była koncepcja Dual LLM autorstwa Willisona.
Główne podobieństwo między CaMeL, a Dual LLM dotyczy architektury. Oba rozwiązania wykorzystują Quarantined LLM, Privileged LLM oraz Controller. Autorzy CaMeL zauważyli jednak pewne problemy w podejściu Dual LLM, które należało rozwiązać – dlatego rozszerzyli i udoskonalili ten bazowy model.
Przepływ danych i sterowania
Aby dobrze zrozumieć problemy obecne w architekturze Dual LLM, trzeba poznać pojęcia przepływu sterowania (ang. control flow) i przepływu danych (ang. data flow). Przepływ sterowania to „plan działania” stworzony w odpowiedzi na zapytanie użytkownika. Zawiera kroki i akcje niezbędne do osiągnięcia celu, na przykład:
- Odczyt danych z bazy,
- Streszczenie tekstu lub ekstrakcja danych,
- Wykonanie kodu,
- Odczyt lub wysłanie e-maila.
Z kolei przepływ danych dotyczy tego, jak dane są przetwarzane, transformowane i gdzie są przesyłane na kolejnych etapach.
Poniższy diagram pochodzi z oryginalnej publikacji i dobrze ilustruje różnicę między tymi przepływami:
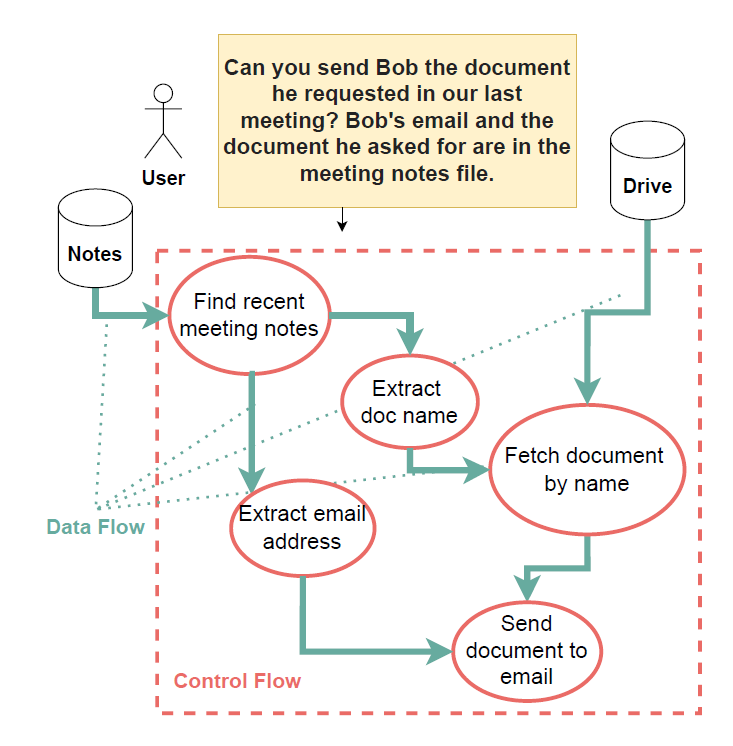
Aby system był bezpieczny przed atakami typu prompt injection, należy zabezpieczyć oba przepływy. Problem w tym, że Dual LLM chroni wyłącznie przepływ sterowania, obsługiwany przez Privileged LLM. Tymczasem przepływ danych pozostaje pod wpływem Quarantined LLM – bez żadnych ograniczeń. Oznacza to, że atakujący nie może zdecydować o tym, jaka akcja zostanie wykonana (np. wysłanie e-maila), ale może wpływać na dane wykorzystywane w tej akcji (np. na adresata wiadomości). Nietrudno zauważyć, że jest to poważny problem.
Architektura CaMeL
Aby rozwiązać ten problem, CaMeL wprowadza pojęcie capability – czyli metadanych przypisanych do wartości. Capability zawiera informacje o pochodzeniu danych (skąd pochodzą, która funkcja je wygenerowała) i uprawnieniach (kto może je odczytać lub zmodyfikować).
Poniższy diagram, również pochodzący z publikacji, przedstawia ogólny schemat działania CaMeL:
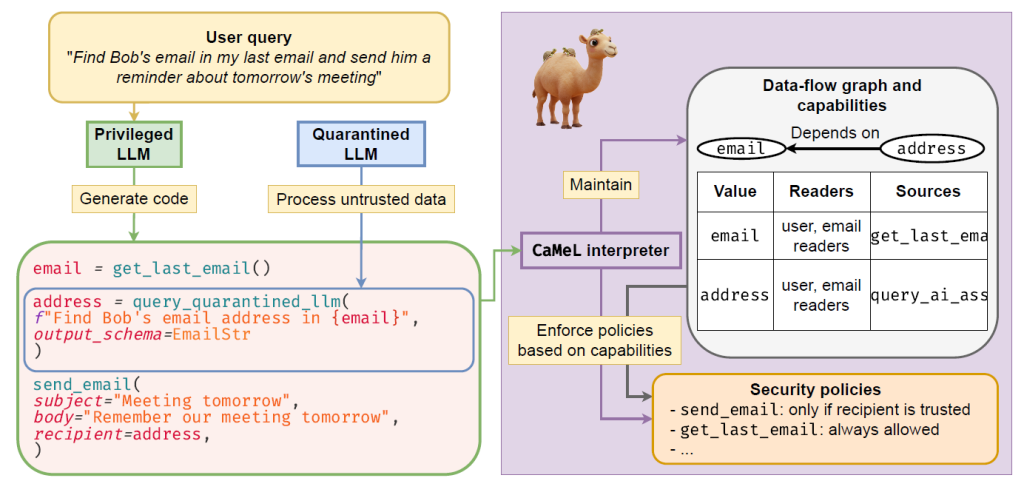
CaMeL działa używając najpierw Privileged LLM, który tłumaczy zapytanie użytkownika na kod w pseudo-Pythonie, który reprezentuje przepływ sterowania. Ten kod wykonywany jest przez interpreter CaMeL – i to właśnie zabezpiecza przepływ sterowania. Następnie CaMeL interpreter wykorzystuje Quarantined LLM do przetwarzania niepewnych danych. Jednocześnie śledzi diagram przepływu danych i przypisane do każdej zmiennej capabilities. Na tej podstawie egzekwuje polityki bezpieczeństwa zapisane również w Pythonie – to właśnie chroni przepływ danych.
Na przykład: nawet jeśli atakujący za pośrednictwem Q-LLM zmodyfikuje odbiorcę tajnej wiadomości, interpreter CaMeL jej nie wyśle, ponieważ adres atakującego nie widnieje w capability jako dozwolony odbiorca.
Nie wszystko wygląda tak różowo
CaMeL nie jest systemem, który chroni przed każdym możliwym typem ataku. W szczególności nie zabezpiecza przed atakami typu text-to-text. Przykładem może być prompt injection, który instruuje Q-LLM, by błędnie podsumował e-mail. Niemniej jednak, diagram przepływu danych tworzony przez CaMeL może posłużyć do przedstawienia użytkownikowi źródła danych, co znacznie ułatwia wykrycie manipulacji. CaMeL nie jest też systemem całkowicie autonomicznym – w realistycznej implementacji użytkownik co jakiś czas będzie musiał potwierdzić wybrane akcje albo doprecyzować zamiary wobec systemu.
Ale są też miłe bonusy
Architektoniczny podział na Privileged i Quarantined LLM niesie za sobą kilka dodatkowych, nieplanowanych korzyści. Podczas gdy faza planowania wymaga zaawansowanego, prawdopodobnie dużego i kosztownego w użyciu modelu LLM, inne zadania mogą być wykonywane przez dużo prostszy i tańszy model. To oznacza, że Privileged LLM może działać jako usługa w chmurze, ale Quarantined LLM może działać lokalnie. A ponieważ P-LLM nigdy nie ma styczności z niepewnym wejściem (na przykład zawartością wewnętrznych maili), żadne poufne dane nie trafią do dostawcy zewnętrznego. To dość nieoczekiwany bonus do prywatności – dane np. z e-maili lub baz danych mogą być przetwarzane lokalnie i pozostać w obrębie infrastruktury organizacji. Na zewnątrz trafią jedynie zapytania użytkownika.
Choć nie jest to złoty środek rozwiązujący wszystkie problemy z bezpieczeństwem LLM-ów, CaMeL wydaje się solidną odpowiedzią na ataki prompt injection uderzające w przepływ sterowania i danych.
Podsumowanie
Zespół DeepMind wykonał świetną pracę, rozwijając wcześniejsze koncepcje Willisona. Moim zdaniem CaMeL to duży krok we właściwym kierunku, jeśli chodzi o bezpieczeństwo systemów opartych na LLM. Przypomina o dobrych, klasycznych zasadach inżynierii bezpieczeństwa – łatwych do zapomnienia w czasach, gdy jedna SI łata błędy innej SI. To całkiem miła odmiana.
Dzięki za przeczytanie i już teraz zapraszam do kolejnych artykułów – mam nadzieję, że pojawią się wkrótce!
Zdjęcie na początku posta należy do użytkownika Mariakray na Pixabay.